

Often when I talk to organizations that are looking to implement data science into their processes, they often ask the question, “How do I get the most accurate model?”. And I asked further, “What business challenge are you trying to solve using the model?” and I will get the puzzling look because the question that I posed does not really answer their question. I will then need to explain why I asked the question before we start exploring if Accuracy is the be-all and end-all model metric that we shall choose our “best” model from.
So I thought I will explain in this blog post that Accuracy need not necessary be the one-and-only model metrics data scientists chase and include simple explanation of other metrics as well.
Firstly, let us look at the following confusion matrix. What is the accuracy for the model?
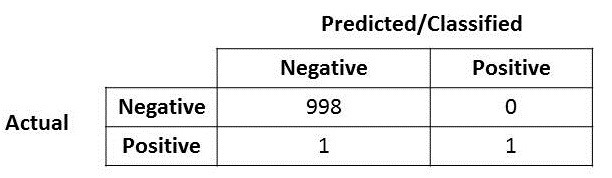
Very easily, you will notice that the accuracy for this model is VERY high, its at 99.9%!! Wow! You have hit the jackpot and holy grail (*scream and run around the room, pumping the fist in the air several times*)!
But….(well you know this is coming right?) what if I mentioned that the positive over here is actually someone who is sick and carrying a virus that can spread very quickly? Or the positive here represent a fraud case? Or the positive here represents terrorist that the model says its a non-terrorist? Well you get the idea. The costs of having a mis-classified actual positive (or false negative) is very high here in these three circumstances that I posed.
OK, so now you realized that accuracy is not the be-all and end-all model metric to use when selecting the best model…now what?
Precision and Recall
Let me introduce two new metrics (if you have not heard about it and if you do, perhaps just humor me a bit and continue reading? :D )
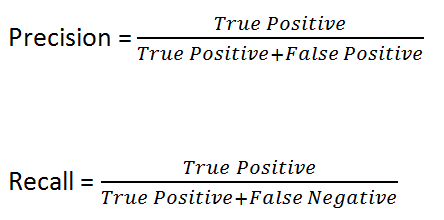
So if you look at Wikipedia, you will see that the the formula for calculating Precision and Recall is as follows:
Let me put it here for further explanation.
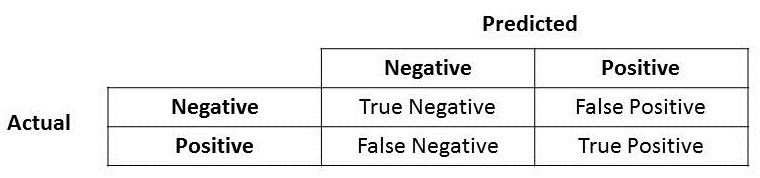
Let me put in the confusion matrix and its parts here.
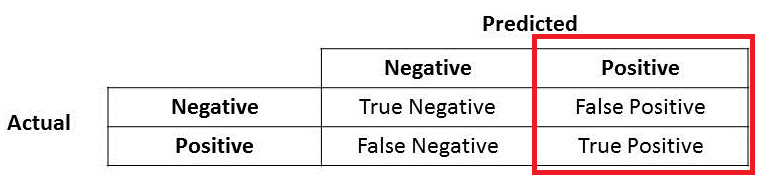
Precision
Great! Now let us look at Precision first.

What do you notice for the denominator? The denominator is actually the Total Predicted Positive! So the formula becomes
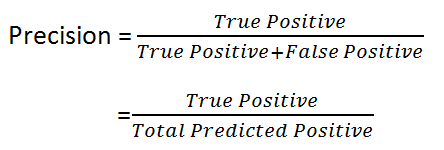
Immediately, you can see that Precision talks about how precise your model is out of those predicted positive, how many of them are actual positive.
Precision is a good measure to select the "best" model, when the costs of False Positive is high. For instance, email spam detection. In email spam detection, a false positive means that an email that is non-spam (actual negative) has been identified as spam (predicted spam). The email user might lose important emails if the precision is not high for the spam detection model.
Recall
So let us apply the same logic for Recall. Recall how Recall is calculated.


There you go! So Recall actually calculates how many of the Actual Positives our machine learning model has captured through labeling it as Positive (True Positive). Applying the same understanding, we know that Recall shall be the model metric we use to select our best model when there is a high cost associated with False Negative.
For instance, in fraud detection or sick patient detection. If a fraudulent transaction (Actual Positive) is predicted as non-fraudulent (Predicted Negative), the consequence can be very bad for the bank.
Similarly, in sick patient detection. If a sick patient (Actual Positive) goes through the test and predicted as not sick (Predicted Negative). The cost associated with False Negative will be extremely high if the sickness is contagious.
F1 Score
Now if you read a lot of other literature on Precision and Recall, you cannot avoid the other measure, F1 which is a function of Precision and Recall. Looking at Wikipedia, the formula is as follows:
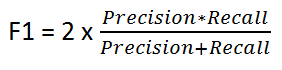
F1 Score is needed when you want to seek a balance between Precision and Recall. Right…so what is the difference between F1 Score and Accuracy then? We have previously seen that accuracy can be largely contributed by a large number of True Negatives which in most business circumstances, we do not focus on much whereas False Negative and False Positive usually has business costs (tangible & intangible) thus F1 Score might be a better measure to use if we need to seek a balance between Precision and Recall AND there is an uneven class distribution (large number of Actual Negatives).
Why Not Accuracy?
First, let us look at the formula for Accuracy.
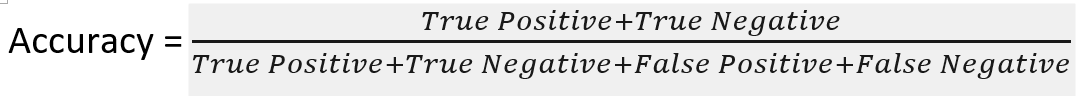
If you look at the numerator, both True Positive and True Negative can contribute to higher accuracy thus an accurate model maybe due to high True Negatives rather, and in most business circumstances, having a high True Negative does not contribute much value to business, for instance, being able to accurately predict that a customer is not going to respond to marketing campaigns. In most business circumstances, what matters most is the True Positives rather.
How to Choose Which Metrics?
Ok here is a set of questions you need to ask yourself, to decide the model selection metrics.
First Question: Does both True Positive and True Negatives matters to the business or just True Positives? If both is important, Accuracy is what you go for.
Second Question: After establishing that True Positive is what you are concerned with more, ask yourself, which one has a higher costs to business, False Positives or False Negatives?
If having large number of False Negatives has a higher cost to business, choose Recall.
If having large number of False Positives has a higher cost to business, choose Precision.
If you cannot decide or thinks that its best to reduce both, False Negatives and False Positives then choose F1.
Hope the above two questions will simplify which metrics to choose.
Conclusion
I hope the explanation will help those starting out on Data Science and working on Classification problems, that Accuracy need not always be the metric to select the best model from.
If you have found this article useful, do consider sharing it and any feedback is welcomed!
If you want to understand Gradient Descent another important concept in Machine Learning, I have written a blog post on it. Else if you just started out, you may want to know how to do a good Exploratory Data Analysis (EDA).
I hope the blog has been useful to you. I wish all readers a FUN Data Science & Artificial Intelligence learning journey and do visit my other blog posts and LinkedIn profile. Consider subscribing to my newsletter as well. Thank you! :)