
I have been mentoring many "green" data professionals for the past few years. I notice that there is a handful of the recent graduates (degrees or bootcamps) that is caught by this mental trap and that is,"Always go for the most COMPLEX machine learning model!"

For instance, some of the trainees will always go for Stepwise Regression (Bi-Directional Elimination) to estimate Customer Lifetime Value. When you ask them for the reasons why they are not testing with Forward Selection and Backward Elimination as well, the usual answer is,"I did not try because I thought that Stepwise Regression is sufficient given its complexity."

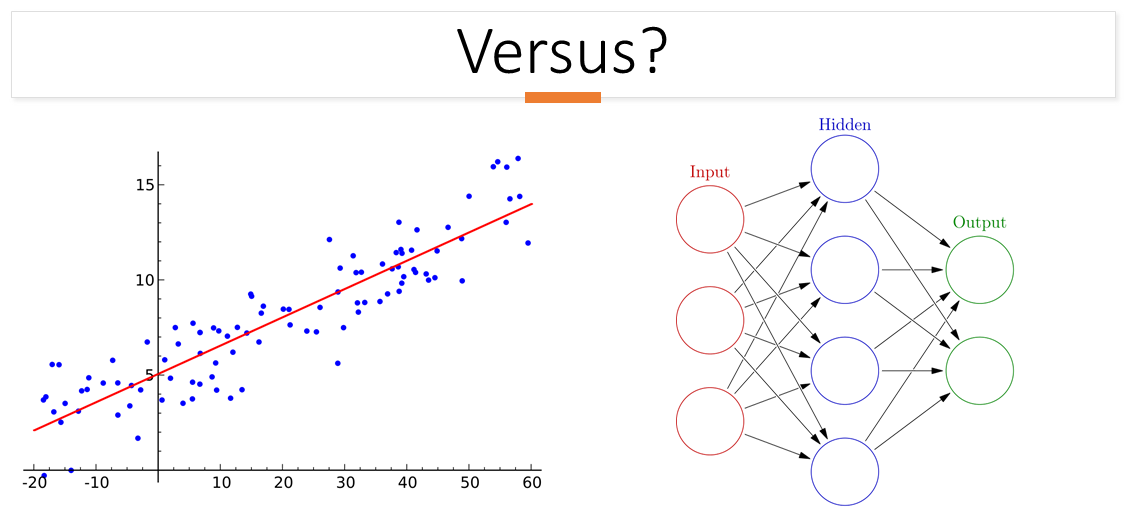
So let me set this straight. When we are doing Supervised Learning, we have a target (Y) and several features (Xs). Our job as a Data Scientist is to find the "hidden" relationship between the target, what we want to predict and the individual features. That means we are finding the relationship between Y and to the different Xs. Now I do not deny that complex machine learning models does help us to model a complicated relationship (mixture of quadratic, cubic, setting "curly" decision boundaries etc) but at the end of the day, we must know that it is a "curve fitting" exercise, as mentioned by Judea Pearl in this article. Now the "curve" need not necessary be curve but can be a linear relationship (a.k.a when X changes, Y also proportionally changes as well).
What I am saying is, we cannot totally discount a machine learning model just because it's not "complex" enough. We should only discount machine learning model when it has been tested and we do not get better "predictions" from it (not modelling the relationship between target and features accurately) or it does not meet the business requirements, for instance not meeting the transparency need or cost of implementation is prohibitive.
Conclusion is, as a data scientist, we need to test all possible machine learning algorithms, regardless of its "complexity" (usually defined by how complicated the maths is behind the scene) as each classes of machine learning model provides different ways to "curve fit" the hidden relationship between target and features.
Do keep this in mind at all times! Have fun in your Data Science learning journey! If the post have been useful, do share it and if you'll like to link up, can look for me on LinkedIn.