

As many of you know, I conduct training in a few institutions in Singapore. For instance, NUS SCALE, SAS Institute and SMU Academy. A frequent comment that participants make during our discussions is,
“There is a myriad of terms out there — Big Data, Artificial Intelligence, Machine Learning, Data Science, Data Analytics etc. It is very challenging to make sense of them and also how they are different from each other.”
Especially, during most discussions, the group thought they were talking about the same thing, but it was not actually the case!
In this column, I will attempt to demystify these popular terms so as to give readers a better understanding of what they constitute and, hopefully, as more people are onboard with what these terms are, there will be more meaningful discussions on them. A very important note is that the following are my own definitions and may differ from others, but the definitions I have so far were formed through my work experiences in the field.
Data Science
Let us start with Data Science. Ok, first thing first, let me state that I do not see any difference between Data Analytics and Data Science. They are referring to the same thing. What is Data Science? Data Science is actually the transformation of data through maths and statistics into products that we can use to make better decisions. For instance, insights, visualization, probability scores or estimates. The main goal is to use data to make informed business decisions. The diagram below simplifies the understanding.

Machine Learning
Let us move on to the next term from here, Machine Learning. Inside the “Maths & Statistics” part we have the machine learning models. So what does machine learning do? There are three branches of Machine Learning:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Supervised Learning
Let us start with supervised learning. Now, for supervised learning, you have to work with what is known as labelled data. Labelled data consists of two parts — a single column known as the target and multiple columns known as features. The dataset needs to be structured in that way before it is ‘fed’ into the relevant machine learning model.

The target is something you wish to know as early as possible so that you can act when it is not favorable. Here are a few examples:
- A bank would like to know if a person is going to default on a credit card loan.
- A company would like to know if its star talent is leaving.
- An e-commerce business would like to know how much spending power a potential customer has before making the right marketing offers.
Now, in order to have a good prediction of the above examples, we need to have some ‘early’ signals. This is where the features come in. Features are what we believe can help us peek into the future. For instance, in the credit card example, the income of loan holder can be a useful feature since we believe that the higher the income, the less likely the loan holder may default on the loan.
So, the target is what we would like to know as early as possible and the features are what will help us know the probability of an event happening (default on loan repayment) or an estimate of a value we are interested in, as seen in the e-commerce example (estimating the customer’s spending power).
Supervised learning helps us understand the relationship between the features and the target.
Unsupervised Learning
Unsupervised learning deals with unlabelled data. Great! Now you have come across both labelled data and unlabelled data, this gives me the opportunity to explain the difference. Labelled data, as mentioned, has both features and a target whereas unlabelled data only has the features. Yes, the difference between the two is labelled data has a target and unlabelled data does not have one.

So what do we do with the features here? Unsupervised learning is a way for us to find patterns in our data. For instance, for a supermarket we can use unsupervised learning to find out which products are frequently bought together, or the segments that make up the supermarket’s clientele. Namely, based on the features provided, the data analyst/scientist can find out what are the types of customers that they are serving. For instance, health-conscious, families, singles etc.
Reinforcement Learning
Reinforcement Learning is not a newly-coined term but receives a lot of mention these days because of Artificial Intelligence.
Let us start with an agent. The human will now provide the agent an objective function, for instance, maximize the score of a computer game the agent is playing or finding an object in a maze in the shortest amount of time. With the objective function established, the agent will now start operating and while it is taking different actions or interactions with the environment, it will get feedback on whether it is closer or further away from the objective. For instance, if we put the agent in a maze, it will take different available directions in the maze and it will receive feedback saying whether it is closer or further away from the ending point in the maze. You can see from here why it is called reinforcement learning, because it will continue taking positive actions to reach the objective and avoid negative actions wherever possible.
Different from Supervised and Unsupervised Learning, Reinforcement Learning requires an objective function, usually to maximise or minimise certain results. Data is collected along the way and analyzed to determine the optimal solution towards the objective function. These are the main differences between them.
Deep Learning
Most of you have heard about this term called Deep Learning in recent years. Deep learning is not totally new. Deep learning is a form of neural network. Neural networks were created back in the 1940s with the brain as a blueprint. The basic neural network only has three layers. The first layer takes in the input data and passes it to the second layer known as the computation layer, then followed by the last layer which is the output layer (see diagram below).
In recent years, because of the increase in computation power and the amount of data collected, we can now tap on the potential of neural networks, especially since we can now add in more computation layers. Deep Learning is actually a neural network with multiple computation layers. Computation layers can have many ways of computing the data passing through them, which is why there are different types of neural networks these days. For instance, the Recurrent Neural Network, which is very good with sequential data such as languages, and the Convolutional Neural Network which is very good with images, creating tools such as facial recognition and object recognition.
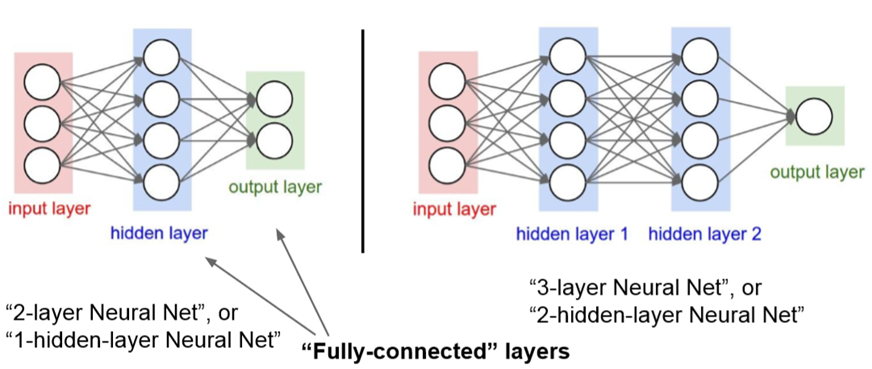
Referring to the diagram above, on the left is the traditional Neural Network. On the right, once we add multiple computation (also known as hidden) layers, the Neural Network starts to get deep. Hence, the name Deep Learning.
Artificial Intelligence
Here comes the star of the show, Artificial Intelligence. What is Artificial Intelligence? Artificial Intelligence is about teaching a machine to perform like human intelligence. It involves machine learning, reasoning methods, knowledge graphs, philosophy, algorithms and a lot more. There are actually three levels of Artificial Intelligence.
- Level 1: Artificial Narrow Intelligence (ANI)
- Level 2: Artificial General Intelligence (AGI)
- Level 3: Super-intelligence
Artificial Narrow Intelligence
Artificial Narrow Intelligence, ANI, are what most people are talking about these days. They are the ones that are generating a lot of news and magazine articles. ANI, are artificial intelligence that humans have built, to replace humans in a SINGLE task. For instance, playing a specific chess such as GO, flipping burgers only etc. ANI are very good with a specific task and nothing else. ANI are what I would call, smarter automation. Some of the tasks can now be automated and be taken up by ANI, which is good news, because most of these tasks are repetitive and boring. They free up working time for humans, giving them opportunities to move on to tasks that require more human touch, tasks that require more critical thinking, design thinking, creativity, empathy and more. It will definitely increase the productivity of humans.
Artificial General Intelligence
Artificial General Intelligence, AGI for short, is the holy grail for most Artificial Intelligence researchers. AGI displays human-like intelligence, for instance an AGI can go to anyone’s kitchen and still figure out how to make a cup of coffee, whereas for ANI, it can only make a cup of coffee in a very specific kitchen and nowhere else.
We are still a very long way from building AGI given the current technology that we have currently, in my opinion. The reason is, currently we have a huge breakthrough in the area of machine learning, given the multi-layer Neural Network (Deep Learning, see above) but AGI is much more than Deep Learning. Researchers have to know how to teach the machine to build abstractions and relations from the data that is collected. Tools such as reasoning methods, knowledge graphs, control theory can help with that but we are still a distance away from including them into the apparatus of AGI.
Having said that, I do believe it is time that we start discussing and paying more attention to how we are going to build AGI, to ensure it is for the benefit of humankind. In fact, there is now a movement in advocating for ethics, explain-ability, transparency in the usage of artificial intelligence. Most governments have now started to work on such research and usage frameworks as well, which is very encouraging.
Super-Intelligence
Super-intelligence comes about when there is no control over how we grow, equip and manage our AGI and thus they gained the momentum to become more intelligent (i.e. becomes smarter than any humans). There is a lot of discussion on this right now and if you want to get up to speed, I recommend the book “SuperIntelligence” by Nick Bostrom, a Swedish philosopher at the University of Oxford. Inside, he painted many scenarios where Super-intelligence might go wrong. (Side note: after reading the book, you will start seeing paperclips in a different perspective.) My opinion after reading the book is that there is no need to panic, we just need to pay more attention to how we build our AGI and this is where AI ethics come into the picture, imbuing our AI scientists and engineers with morals and ethics, paying more attention to the impact of their work on stakeholders.
I, for one, am in favor of having AGI and humans working together (in fact, there is a term for it and it is called "Augmented Intelligence"), side-by-side creating more synergy and, in turn, creating bigger and positive impact on society.
Conclusion
I hope the above helped to clarify some doubts that you might have had. As you can see, Machine Learning is just a branch of Artificial Intelligence. Currently we are having a lot more breakthroughs in Machine Learning which creates the illusion that we are nearing the human-like intelligence called AGI but in actual fact we are still a distance away, in my opinion.
And also please, do not take my word as final, go forth and read up more to understand the field. I can only say that the understanding I have so far of these terms are accumulated across many years of working in the field and things are changing rapidly so your understanding and definitions should get updated along the way.
There are a few more terms I have not clarified in this post, such as Big Data. I will attempt to clarify them later. Thank you for taking the time to read through the post. I wish you, the reader, a pleasant and rewarding journey in understanding the field of Artificial Intelligence.
I hope the blog has been useful to you. I wish all readers a FUN Data Science & Artificial Intelligence learning journey and do visit my other blog posts and LinkedIn profile. Consider subscribing to my newsletter as well. Thank you!
Originally published at https://makerspace.aisingapore.org on October 6, 2019.