

One question I get a lot is why model validation is important in a data science process, specifically in supervised learning.
In this blog post I will be talking about model validation and why are data scientists so concerned about it. I will not be going into the technical details but the reason and its importance. If you are looking for the technical details on the possible model validation techniques, you can check out this post.
What is Data Scientist concern with?
For supervised learning, Data Scientist is concerned with two things about the final model selected. That is over-fitting and under-fitting. I called it the Goldilock Problem. What are they to the layman?
Background
From the layman's perspectives, when we are doing predictive analytics especially, we are trying to use existing data and see if any of them has a relationship with something of concern, which is the target. For example, in banks we are sifting through the usage and payment behavior of credit card customers, to see if there are certain circumstances where it can signal to the bank in advance, that a credit card customer is likely to default on their credit card customers.
From modeling perspectives, we are training up a model that can capture as much of the signals as possible from the data and removed the noises i.e. we want the signals and ignore the noises as much as possible. So going forward, if the model sees something similar to the "signal" captured during the training phase, there is high reliability of the prediction results.
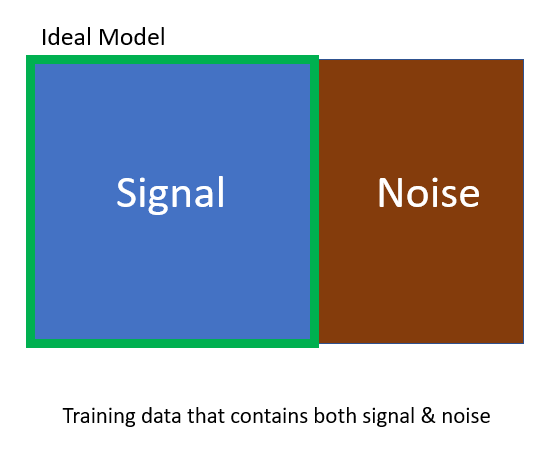
Ideal Model
Below is a very simple diagram to show what data scientists want to do ideally in supervised learning. The green box represents the ideal model where it is able to capture all the signals.
Overfitting
Overfitted model happens when the model captured a lot of the noises, mistaken it as "signal", a mistaken identity. Below shows how it looks like.

This means that the overfitted machine learning model, if used for prediction, may give wrong prediction results due to mistaking the noises, which has no relevance/relationship to the target, as signals.
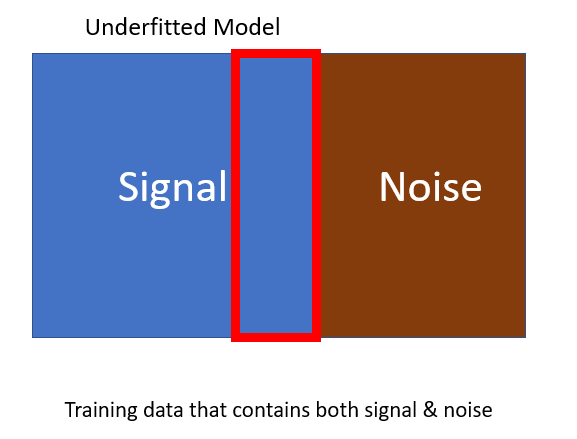
Underfitting
Underfitting happens when not enough signals are captured. Think of it this way, the more accurate signals we see, the better the accuracy of the prediction. Not capturing enough signals means information lost, to make the model accuracy better. The diagram below shows an underfitted model.
Summary
Here is a quick summary before moving on:
Ideal Model - Captured ALL the Signals and ignore ALL the Noises
Overfit Model - Mistaken a lot of Noises as Signals
Underfit Model - Not capturing enough Signals
Model Validation
Note that in reality, the signals and noises are not presented so readily. So model validation is the tool or necessary phase to go through, during model training, to ensure that the final model that we have chosen, does not overfit or underfit, getting a model that is "just right", similar to what Goldilocks says when she visited the house of the three bears. :)
Again, if you are looking for the technical details on the possible model validation techniques, you can check out this post.
I hope by now you have a better appreciation of the model validation phase and will pay more attention to it if you have not.
Thanks for the kind support, taking the time to read till here. If you found this to be useful, consider subscribing to my newsletter. Stay in touch on LinkedIn and Twitter! Have fun in your learning journey! :)