
I have written an overall view on the skills and knowledge needed by a data scientist. You can find the article here.
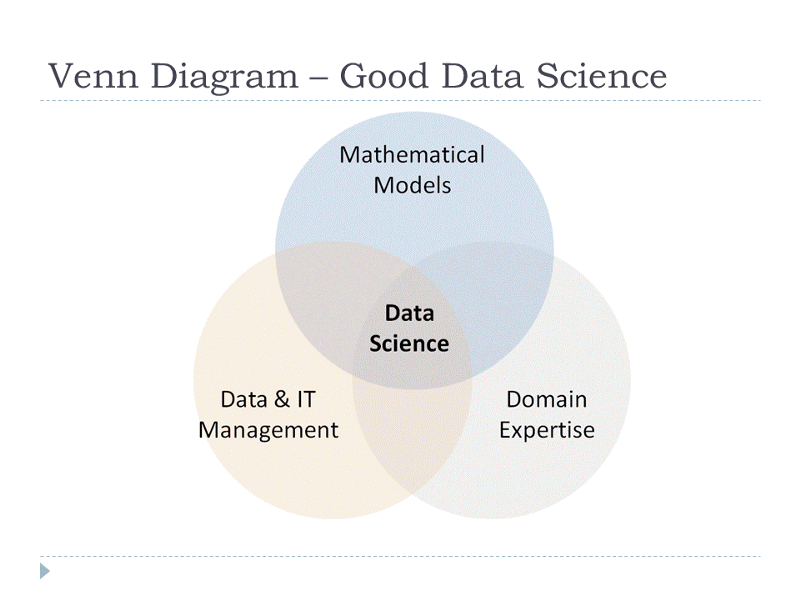
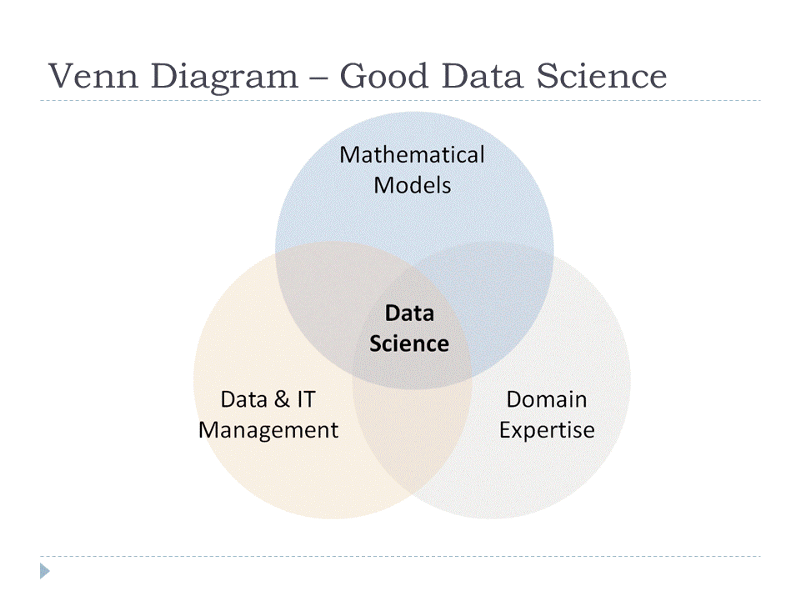
Quick catch-up, this was the Venn Diagram that I shared in my previous post.
Introduction
If you look at data science in more details, we are actually using mathematical models to model (and hopefully through the model to explain some of the things that we have seen) business circumstances, environment etc and through these model, we can get more insights such as the outcomes of our decision undertaken, what should we do next or how shall we do it to improve the odds. So mathematical models are important, selecting the right one to answer the business question can bring tremendous value to the organization.
One FAQ I get is mathematics is so broad, where shall I start? You start of with Linear Algebra and Calculus.
1 — Linear Algebra & Calculus
Yes, first and foremost, like most come-back Kung-Fu movies (where the protagonist got defeated by a big bad boss thus was down and out. During this down and out period, he found a brilliant sensei to teach him Kung-Fu, LEARN KUNG-FU, then defeat the big bad boss after, THE END) that you have seen, the sensei would always start from the basic.
Linear algebra & calculus would be considered the most basic. This is especially true given the “Deep Learning” environment that we are in. Deep learning requires us to understand linear algebra & calculus, to understand how it works, for example forward propagation, backward propagation, hyper-parameters setting etc. Having a good foundation helps us to understand how these models work, what assumptions are made and how the parameters are derived. Back in my uni days, I studied Linear Algebra and Calculus but did not see the relevance to my work until now. Sure wished I had spent more time on it.
So what should the potential data scientist learn? Here is a list for you.
For linear algebra, there are matrix operations (plus, minus, times, divide), scalar product, dot product, eigen-vectors and eigenvalues.
For calculus, the data scientist need to understand various differentiation (to second-order derivative), integration, partial differentiation. While going through some of the materials, they do touch on mathematical series such as Taylor series. If you are interested to learn more about mathematical series, Wikipedia is pretty comprehensive. Check the link.
Calculus and linear algebra are used greatly when we look at designing the loss function, regularization and learning rate of the machine learning/statistical models.
2 — Statistics
Well, how can one run away from statistics when doing analysis and it needs no further introduction. From experience, understanding of statistics is needed when we intend to do experiments and testing such as in marketing, we have the A/B testing. We generally want to understand if there are any statistical difference between two samples, or after certain “treatment”, did it create a statistically significant effect.
So the areas to learn are simple statistics like measurement of centrality, distributions and different probability distributions (Weibull, Poisson etc), Baye’s Theorem (there’s a strong emphasis on it when it comes to learning about Artificial Intelligence later), hypothesis testing etc.
3 — Machine Learning/Statistical Model
In my undergraduate years, I studied Econometrics, which is the closest to a machine learning/statistical model. In that study, I came across linear and logistic regression. The module covers very heavily in the assumptions of the regression models namely, heteroscedasticity, autocorrelation, E(e) = 0 and multi-collinearity. Why these assumptions are important is because in training the model, we seek to achieve what is called BLUE (Best Linear Unbiased Estimates) parameters, namely the coefficients including the intercept.
But when I moved on to machine learning models, for a course on regression models, there is no emphasis on these assumptions anymore, instead there is a heavy emphasis on setting up the loss function, the rationale behind regularization, gradient descent and learning rate.
Coming back, learning about machine learning models is a must for any data scientist given that they would need to propose the machine learning models that can help to provide insights to the organization. The data scientist would need to convert the business objectives given and turn them into machine learning models for answers and insights.
There are generally two types of machine learning models, supervised & unsupervised learning models.
Supervised learning models
Assuming you have two sets of data. Set A has the behavior data in Period 1 and outcomes in Period 2. Set B only has the behavior data in Period 3 (or 2) but do not have any outcomes in Period 4 (or 3).
Using Set A, you are going to train a model that just by looking at the behavior, be able to “predict” (or give a probability) the outcome. With the model trained out, you will “score” the behavior data and try to “predict” (or have a probability) on which outcome is likely.
Models that can be used are called supervised learning models. Its supervised because the outcomes from Set A “supervised” the model to come up with good predictors.
Unsupervised learning models
So you might have guessed, for unsupervised learning models, there is no “outcomes” on the Set A data and it is usually not used with a Set B data. In fact, the unsupervised learning models is just trying to find out patterns that are inside Set A, patterns that are discerned by the model’s training algorithm.
Moving from Business Objectives to Modelling Objectives
Having a good understanding of supervised and unsupervised model, the data scientist would need to know in each business objectives given, which machine learning models to use, how to use them, in what sequence to use them so as to achieve the business objectives given. A lot of the training programmes that I have seen usually used a single model chosen to achieve business objectives, for instance, in creating a email marketing response model, either a logistic regression or decision tree or support vector machine is chosen to build it. This has created a blind spot that its going to be one machine learning model for each business objectives which need not necessary be the case.
The ability to recommend which models to used and structure out the modelling objectives based on business objectives comes with experience. So for any potential data scientists, do start working on it.
Model Training
In machine learning, each machine learning model that you come across have many “knobs” and “switches” for you to tune or flip during the training of your model. These “knobs” and “switches” are known as hyper-parameters. Data scientist with a good background in mathematics would have a high comprehension as to how to turn these “knobs” and “switches” to get the “best” models. In fact, if they have a good background, they may come up with their own loss function and set up their own stochastic gradient descent method, the two key components of training the different machine learning models (mainly supervised).
Model Selection Metrics
Most of the time, we can train several different models (given the objectives and the hyper-parameters), we would then need to understand how model selection metrics are calculated and what kind of models do they favor.
Choosing the best model need not always be based on accuracy alone, because in real life, the costs of predicting positive wrongly can be very different from predicting the negative wrongly. For instance, in an epidemic, a test that can reduce false negatives is much needed than a test that can be highly accurate because it gets a lot of true negatives.
4 — Operation Research
We all work in an environment where decisions are needed to be made constantly. Being able to deploy mathematical models to help make better decision is what operation research is about. What are some of the examples of operations research? They are optimization, game theory, forecasting, queuing theory, simulation, graph theory etc. Of course, operation research also includes statistical/machine learning models to help model the business environment so that a reasonable decision can be made. This is a mathematical field altogether and requires a lot of study that is non-statistical.
I believe the data scientist should be able to use these models, with parameters supported by data so that “better” decisions can be made, helping the business organization to achieve their business objectives.
Conclusion
At the end of the day, the data scientist should be well-versed in mathematics and statistics to give him/her the best foundation to build their data science careers. My opinion is that a data scientist most essential skills is the mathematics knowledge, being able to convert the business objectives or challenges into mathematical models and using these models as part of the basis to make the best possible decision.
There will be others who argue that programming is an essential skill which I do not deny but I see that it is essential because we are now using computers to crunch the large amount of data that we have. Imagine without having the mathematical knowledge, to understand how to model the environment, how useful would the programming skill be to the data scientist then?
I hope this gives anyone who is considering a career in data science, to understand what are the mathematics that they need to know in order to be a data scientist. Do have a look at Data & IT management and Domain Knowledge for a complete picture.
I figure since some of you are reading this, you might be interested to know what does Andrew Ng think are the mathematics that is needed to be strong in AI and Machine Learning. Here is the link.
Thanks for your kind support in reading till here. Do consider subscribing to my newsletter. I wish you all the best in your Data Science journey! If the article is useful, do share with your friends and consider giving me a shout out at LinkedIn or Twitter. :)
(Note: This post was written previously for Medium and this is an edited version of it. Updated as well. Original post can be found here.)